Ok so I’ve got an hour off work, time to try and live blog this. But here is the inception of the idea.
This exists in many ways, but I want to make the easiest, fastest, and cheapest using Open AIs Whisper. So I can ramble on, and then turn my rambles (the good parts) into a story. A few uses cases but mostly for Twitter/X.
To start with I told Claude a story and asked it to help make a prompt file. After a few iterations here is where we landed.
M4A to Text Transcription Project Guide
Project Overview
Create a web application that transcribes M4A audio files (commonly used by iPhones) into text. The app will use React for the frontend and Node.js for the backend, with OpenAI’s Whisper for transcription.
File Structure
m4a-transcription-app/
├── client/ # React frontend
│ ├── public/
│ │ └── index.html
│ ├── src/
│ │ ├── components/
│ │ │ ├── FileUpload.js
│ │ │ └── TranscriptDisplay.js
│ │ ├── App.js
│ │ └── index.js
│ └── package.json
├── server/ # Node.js backend
│ ├── src/
│ │ ├── routes/
│ │ │ └── transcription.js
│ │ ├── services/
│ │ │ └── transcriptionService.js
│ │ └── app.js
│ ├── uploads/ # Temporary storage for uploaded files
│ └── package.json
└── README.mdDetailed Steps
1. Set Up Project Structure
mkdir m4a-transcription-app
cd m4a-transcription-app
git init
echo "node_modules/\n.env\nuploads/\n*.log" > .gitignore2. Set Up Backend (Node.js)
mkdir server
cd server
npm init -y
npm install express cors multer dotenv openai
npm install --save-dev nodemon
mkdir src uploadsCreate src/app.js:
// src/app.js
require('dotenv').config();
const express = require('express');
const cors = require('cors');
const transcriptionRoutes = require('./routes/transcription');
const app = express();
app.use(cors());
app.use(express.json());
app.use('/api', transcriptionRoutes);
const PORT = process.env.PORT || 5000;
app.listen(PORT, () => console.log(`Server running on port ${PORT}`));Create src/routes/transcription.js:
// src/routes/transcription.js
const express = require('express');
const multer = require('multer');
const path = require('path');
const { transcribeAudio } = require('../services/transcriptionService');
const router = express.Router();
const upload = multer({
dest: 'uploads/',
fileFilter: (req, file, cb) => {
if (path.extname(file.originalname).toLowerCase() === '.m4a') {
cb(null, true);
} else {
cb(new Error('Only M4A files are allowed'));
}
}
});
router.post('/transcribe', upload.single('audio'), async (req, res) => {
try {
if (!req.file) {
return res.status(400).json({ error: 'No file uploaded or invalid file type' });
}
const { path: filePath } = req.file;
const transcription = await transcribeAudio(filePath);
res.json({ transcription });
} catch (error) {
res.status(500).json({ error: error.message });
}
});
module.exports = router;Create src/services/transcriptionService.js:
// src/services/transcriptionService.js
const { Configuration, OpenAIApi } = require("openai");
const fs = require('fs');
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
async function transcribeAudio(filePath) {
try {
const resp = await openai.createTranscription(
fs.createReadStream(filePath),
"whisper-1"
);
return resp.data.text;
} catch (error) {
console.error('Transcription error:', error);
throw new Error('Failed to transcribe audio');
} finally {
// Clean up the uploaded file
fs.unlink(filePath, (err) => {
if (err) console.error('Error deleting file:', err);
});
}
}
module.exports = { transcribeAudio };Create .env file:
PORT=5000
OPENAI_API_KEY=your_openai_api_key_hereUpdate package.json scripts:
"scripts": {
"start": "node src/app.js",
"dev": "nodemon src/app.js"
}3. Set Up Frontend (React)
npx create-react-app client
cd client
npm install axiosReplace src/App.js:
// src/App.js
import React, { useState } from 'react';
import FileUpload from './components/FileUpload';
import TranscriptDisplay from './components/TranscriptDisplay';
function App() {
const [transcript, setTranscript] = useState('');
return (
<div className="App">
<h1>M4A Transcription App</h1>
<FileUpload setTranscript={setTranscript} />
<TranscriptDisplay transcript={transcript} />
</div>
);
}
export default App;Create src/components/FileUpload.js:
// src/components/FileUpload.js
import React, { useState } from 'react';
import axios from 'axios';
function FileUpload({ setTranscript }) {
const [file, setFile] = useState(null);
const [loading, setLoading] = useState(false);
const handleFileChange = (e) => {
setFile(e.target.files[0]);
};
const handleSubmit = async (e) => {
e.preventDefault();
if (!file) {
alert('Please select a file');
return;
}
const formData = new FormData();
formData.append('audio', file);
setLoading(true);
try {
const response = await axios.post('http://localhost:5000/api/transcribe', formData, {
headers: { 'Content-Type': 'multipart/form-data' }
});
setTranscript(response.data.transcription);
} catch (error) {
console.error('Error uploading file:', error);
alert('Error transcribing file');
} finally {
setLoading(false);
}
};
return (
<form onSubmit={handleSubmit}>
<input type="file" accept=".m4a" onChange={handleFileChange} />
<button type="submit" disabled={loading}>
{loading ? 'Transcribing...' : 'Transcribe'}
</button>
</form>
);
}
export default FileUpload;Create src/components/TranscriptDisplay.js:
// src/components/TranscriptDisplay.js
import React from 'react';
function TranscriptDisplay({ transcript }) {
return (
<div>
<h2>Transcript</h2>
<pre>{transcript}</pre>
</div>
);
}
export default TranscriptDisplay;4. Running the Application
- Start the backend:
cd server
npm run dev- Start the frontend (in a new terminal):
cd client
npm start5. Testing
- Prepare an M4A audio file (you can record one using an iPhone).
- Open the app in your browser (usually at http://localhost:3000).
- Upload the M4A file and click “Transcribe”.
- Verify that the transcription appears in the TranscriptDisplay component.
6. Next Steps
- Improve error handling and user feedback
- Add loading indicators and progress updates
- Implement file size limits and other security measures
- Style the frontend for a better user experience
- Consider adding support for other audio formats in the future
I only called my first AI API yesterday, and it was a lot of fun but I was trying to do too many projects at once. I’ve got a lot that are close to being shippable but need to pick one to refine. Whilst I figure that out I am going to ship another lol.
14:42 –
So we’ve got the prompt file, I will add that to directory and ask Cursor to build the app – let’s see how far we get.
15:07
Ok sorry I got a little distracted fiddling with APIs etc. and getting the file structure right (this is the thing I worry about since I don’t understand each part).
Here is what we have, so far and I’m about to test to see if it actually works. I did try and add drag and drop but not sure that works.
It added the file but: Error transcribing file – sad times!
I’m on slow responses now (after 10 days) I did try and eek them out, but I dare not switch to GTP mino 0 for now.
15:20 – debugging is taking a bit longer than I had hoped. But new UI looks marginally better:
I did also lay down for 5 mins with my cat so there is that.
15:25 adding some debugging
15:28 my meeting has started so gotta take a break. BRB.
15:55: Came out of meeting, debugged a bit. Uploaded file and managed:
Waiting to see if it ever completes this task!!!!
It didn’t. Had to fiddle around with it but then:
15:59:
Rapid. Done. Haven’t deployed it but it’s working, I need a name as I actually want to use this. Before I do, let’s check the cost of this 10min audio:
0.06 cents! Ok that’s quite a lot but also nothing?
17:27 – it’s after work now and consider what to do. I think for now let’s just make the user interface look a bit sexy.
When I get there, is there a good way to price this?
1 hour of content would cost 0.36$. I can afford that for me, not for anyone else…
18:06 – added buttons needs some tweaking but you get the idea.
After getting to this point I was considering binning the project…
Update (8th September)
I wasn’t going to build this any further, but I’ve found myself wanting to use it ALOT recently. Content is king, and this would help me produce a lot of it. I tried to find a good free version and I simply could not find one that just worked with out a sign up (probably due to cost).
I decided to focus on “fastest and cheapest” for now for simply taking an M4A file and giving a cleaned up transcript. Whisper is a A BIT expensive. To reduce I’m going to see the cost with FFMPEG in use (and how quick this is).
FFMPEG is a library that should allow us to remove silences in the audio file before we send them to the API. If there are a lot of silences, this could cut our coast in half.
I did this and got the cost from 0.6 to 0.5 so not a massive win but not too bad.
What I REALLY want to try is assembly API as they suggest their costs are as low as 0.12 per hour. If I can also applying my silence removing here than I should be golden.
OK it seems the Assembly API pulled their “Best Quality” API which is 0.36 per hour. My 10 minute file came out at 0.48 cents (so basically the same as Open AI. However the transcription is DEFINITELY worse.
Let’s try the “nano” model out which is apparently much worse quality… my fingers are very crossed that this will be OK.
Bingo!
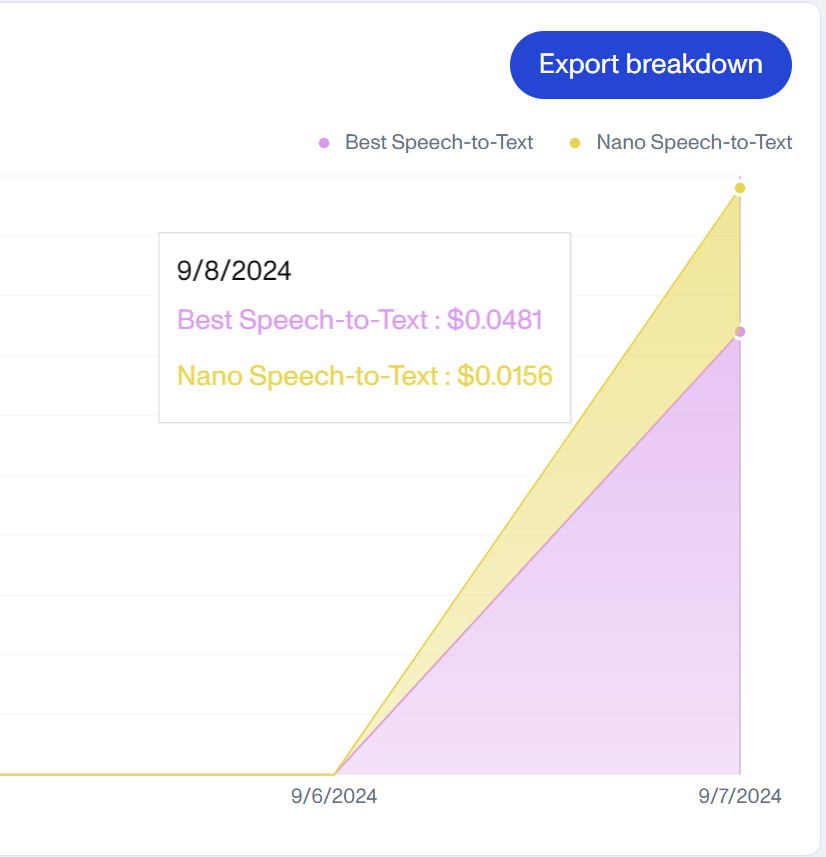
That means a cost of about 0.10 cents per hour of audio combing these methods. We can also do 200 files concurrently. I should add I still have a “cleanup” call to OPEN AIs API but as its 3.5 the costs is miniscule.
Great success, I’m going to save this file as a backup – as this state is something I will want to use for more advanced projects. And it will mean I don’t need to re-install loads of stuff in the future.
Now I need to consider what I am going to price premium at, here is the first ranked competitor. Free version is capped at 10 minutes for free.
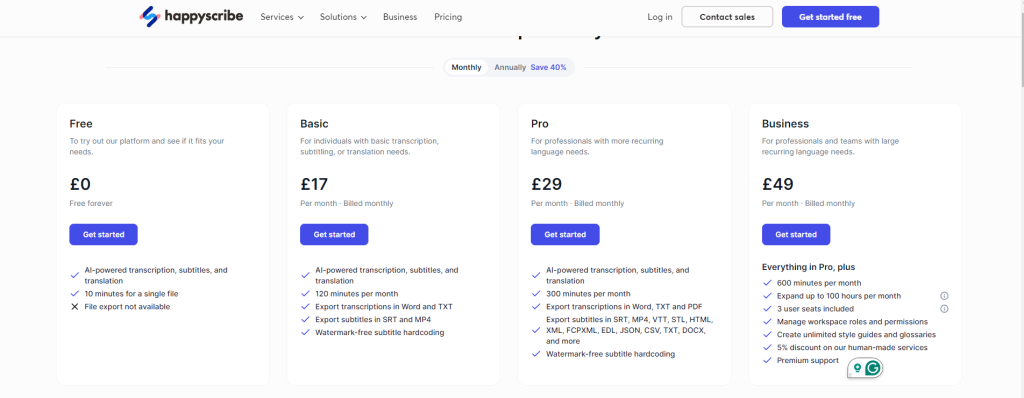
Even on their annual billing they are charging £10 per month (£17 if paid monthly). This seems to be inline with the market. I’d like to do lifetime access, but that is kind of impossible given the costs (unless people use their own API key, but then they might as well build it themselves).
Let’s assume $0.02 per 10 minutes of audio, I can produce 120 minutes of audio for 24 cents. My costs basis is insane. Let me test with a longer file
Leave a Reply